Dustin Ingram
Writing — Speaking — GitHub — SocialInside the Cheeseshop: How Python Packaging Works
October 23 2018This is a transcript of a talk I gave a few times in 2018. #
 |
Hi, I'm Dustin Ingram. |
 |
I'm a member of the Python Packaging Working Group, the Python Packaging Authority, I'm a maintainer, contributor and administrator of the Python Package Index, and I'm a developer advocate at Google. |
 |
I had a pretty hard time coming up with the title for this talk. Not because naming things is hard (although, naming things is hard.) The reason I had a hard time coming up with the title of this talk is because I knew I wanted to talk about Python Packaging, but a lot of people have already given talks about Python Packaging. So many, in fact, that every time I came up with a title for this talk, it seemed like it had already been used. |
 |
At first I thought, what is the core of Python Packaging? I'll call my talk "Python Packaging: Getting the Code You Wrote To the People That Want It Using the Same Language You Wrote It In". |
 |
But that talk has already been given! And that title's pretty long, so I thought maybe I should do something more clickbaity. |
 |
Like, "Python Packaging, In Just Five Easy Steps!" |
 |
But that's been done! I thought maybe I could one-up him. |
 |
I'll do "Python Packaging, In Just FOUR Easy Steps!" |
 |
He did that as well! |
 |
Perhaps I should be encouraging about Python Packaging: "Python Packaging: It's Relatively Painless Now, Go Ahead And Use It". |
 |
Nope, this talk has been given. And "relatively painless" is still painful, so maybe I should instead try to install confidence that it's improving. |
 |
"Python Packaging, We're Still Trying To Make It Better" |
 |
Nope. |
 |
Maybe I should take a stronger approach: "Python Packaging: Let's Just Throw It All Away And Start Over From Scratch". |
 |
It's been done! |
 |
Maybe the problem is too much has changed? I'll do "Python Packaging: Let Me Just Get You Up To Speed On Everything That's Changed Since Last Time". |
 |
Already done. |
 |
Then I figured, maybe not everyone cares about everything in packaging, I'll do "Python Packaging: There's A Lot Of Stuff Here, You Might Not Need All Of It". |
 |
Already a talk. |
 |
Maybe instead I should just keep it simple: "Python Packaging, In the Simplest Terms Possible, For Anyone That Cares". |
 |
It exists. |
 |
Maybe even simpler? "Python Packaging, So Easy A Caveman Could Do It". |
 |
I'm really starting to run out of options at this point. |
 |
Maybe I should stick to something unique about my experience. "Hello. I Am a PyPI Maintainer. At the Very Least, I Should Be Able To Tell You How To Use PyPI". |
 |
OK, one last ditch effort. |
 |
I'll do "Python Packaging", but Indiana Jones-themed, for some reason... and I'll do it in French. There's no way this has been done before. |
 |
... |
 |
So it really seems like everything that could be said about Python Packaging has already been said. At this point I should probably just give you a list of links to these talks on YouTube, and you can go home and watch them at 2x speed. |
 |
And I can just wrap this talk up now. |
 |
In the end, I picked this title, which is really awful, for a number of reasons. |
 |
First of all, it's got an obscure reference to something that makes no sense. Why am I talking about a cheese shop? I know nothing about cheese. |
 |
Second, "Python Packaging" is an incredibly broad and complex subject. Trying to explain how it works is perhaps a lost cause. |
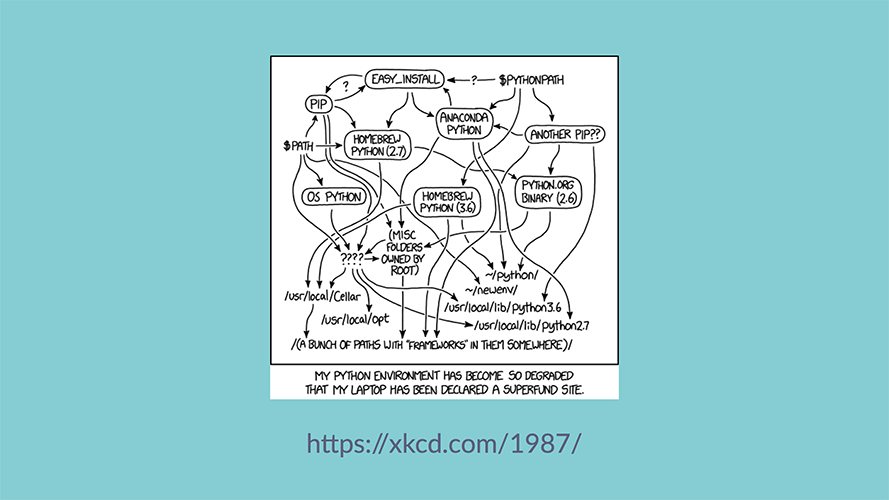 |
And third, I'm making the assumption that Python Packaging actually works! Which has, historically, been the biggest complaint about the topic If you can't read the caption, it says "My Python environment has become so degraded that my laptop has been declared a superfund site". But here's the thing, I think Python Packaging actually works great, and we've just gotten used to how good we have it. |
 |
So I really truly do want to do some Python Packaging archaeology with you all. I want to talk about the evolution of packaging through the years, to provide some context for why things are the way they are And about how at each step, we had a new problem to solve, then a new solution for that problem, which begat a new problem, etc. |
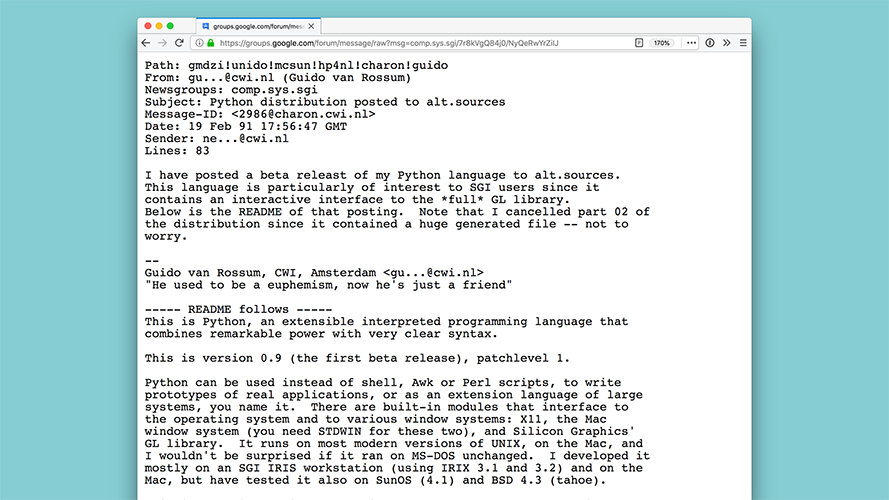 |
So let's go back in time, back to a time when Python was brand new and everything we're familiar with today didn't exist. Back to the beginning where there was just Python. |
 |
Pretty much as soon as there was Python, there was something written in Python. Let's pretend you're the author of this totally awesome library. Nice work! but really, at the moment, this code is only really useful for you. |
 |
So you have a problem: how do you get code to users? This is really the fundamental problem of packaging. Maybe you talk to your friends, and say "Hey, I have this totally awesome library". |
 |
You could email it to someone every time you found someone new that wanted it. But that would pretty quickly become a pain. |
 |
You could put it up on your website somewhere with a link to download. This is nice because you could also add some documentation, etc. But how will people find it if they want it? |
 |
Python was first released in 1991. Google wouldn't be around for another seven years. |
 |
This leads us to a new problem: how do we find Python Code? So what we need is a place where people can go to find interesting Python code... some sort of "index" for "Python packages"... I think we'll call it... |
 |
The Vaults of Parnassus. |
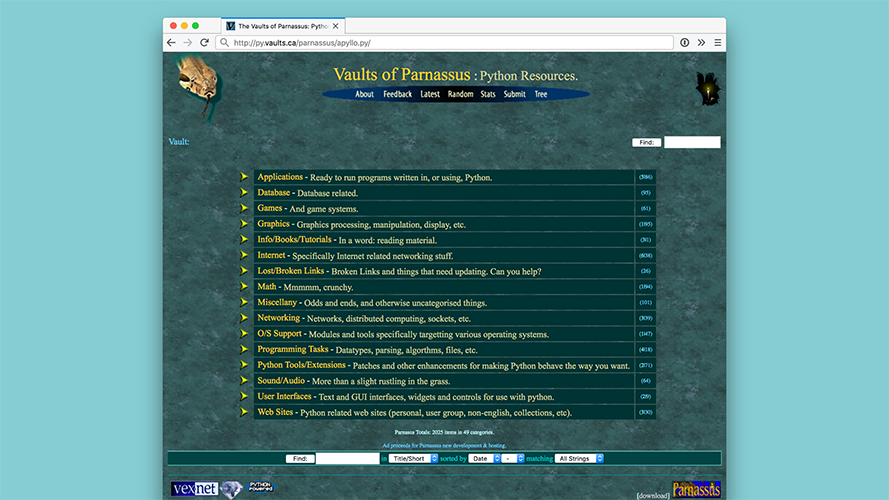 |
This was the first index for Python Software. It was literally an index, which just linked to... something... on other peoples websites. I hesitate to the word "package" here, because at this point what a "package" is, is really loosely defined. The end result is just whatever those people felt like putting on their website. There's no standard, or enforcement of any standard or quality level, etc., which leads us to a new problem. |
 |
At this time, every project came with it's own special little way to build it. Maybe it was a Python script, maybe it was a Makefile, maybe it was just instructions in a text file. This is really painful for users! |
 |
So, at the "1998 international Python Conference" (which would later become PyCon), a little project got started called "distutils", for "distribution utilities". This was included in the standard library in Python 1.6, circa 2000. |
 |
This gave us the somewhat familiar incantation, I think some people have run this without really thinking about what's going on here: it's just a Python script! With a little magic thanks to the standard library. The idea was: why write a domain specific language or add a new config file when you already have the full power of Python at your disposal? Let's just write more Python! (We'll see why in a bit...) |
 |
And this was really just a build tool, to replace those Makefiles. The goal was to make something in a consistent way, that could then be installed. |
 |
The |
 |
This is also known as an "sdist". |
 |
I like to say this like a snake. |
 |
This command might be a little more familiar. |
 |
But pretty quickly it became obvious that sometimes, source distributions weren't going to cut it. Sometimes, source distributions are fine. But sometimes they have so much to do during the build step, possibly even compiling some C code, that it becomes costly to do this every time you want to install some dependency, and it feels wasteful if you're doing it over and over again for the same architecture. |
 |
The solution is built distributions. Instead, you take a distribution that's been pre-built for your architecture, and you just drop it in place, no build step necessary. |
 |
This is also known as a "bdist", for "built distribution". |
 |
And you could create it like this. |
 |
The The first of which is the generic idea of "packaging". By this I mean: how do I get the user to the state right before they run the build command? Where they have everything they need, but it's just not put together yet? |
 |
The original All the platforms they wanted to run Python on already had system-level package managers. I'm talking about Linux package mangers like RPM. They couldn't imagine developers would ever want to do development on platforms that didn't have a package manager. Well, guess what. |
 |
As it turns out, developers love developing on platforms that don't have official package managers, like macOS and Windows. |
 |
There's another problem with this solution. |
 |
Maybe your platform does have a package manager, but packages in platform distributions usually lag behind releases, because once the author has published the code some way, the platform maintainers need to take that and package it up for the specific platform and put into the platform's specific index. And as a user, you want that fresh release now. |
 |
The solution was to create package index just for Python, for authors to publish directly to, and users to get software directly from. We call this, the Python Package Index. |
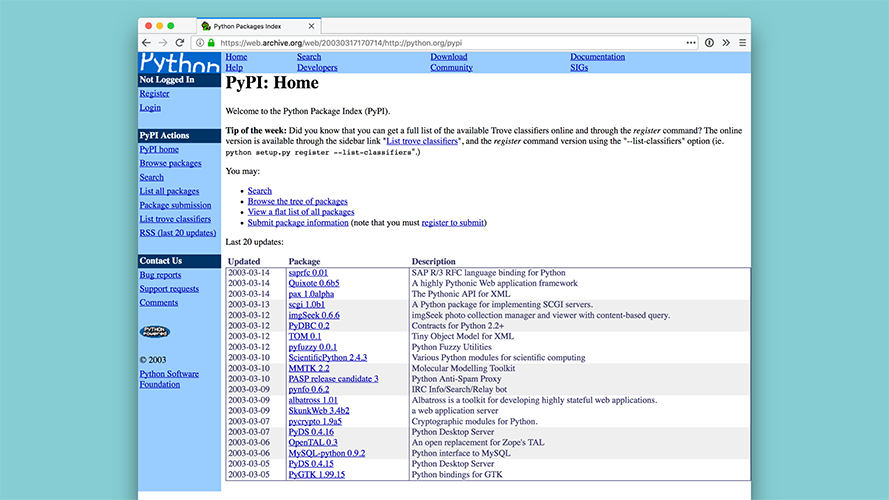 |
Here it is in October 2002. It gave us an official, consistent, and centralized place to "put" Python software. I say "put" because it still links to externally hosted files, but it's got a bit more structure. |
 |
This is also known as PyPI. |
 |
Say it with me: Pie Pea Eye. Not "pie pie", that's something else. Again, naming things is hard. |
 |
PyPI is sometimes called the Cheeseshop. |
 |
This is a reference to this Monty Python skit, where a man goes into a cheeseshop which has no cheese for sale. The joke is that when PyPI was first created, there was nothing in it. Hence, "The Cheeseshop". But it does have stuff in it now, so it's not really even appropriate to call it that anymore. |
 |
The other thing that This makes sense: why bother specifying dependencies when you don't know where to get the dependency from?
Now that we have a package index, it's possible to not only point to some
version of a package somewhere, but it's also possible to distribute
something that does more than |
 |
The
There are some advantages here: because There are some disadvantages, though: monkeypatching is never really a good idea, especially monkeypatching the standard library.
But once we had |
 |
For example, now that we can specify dependencies easily, we make them easier to install as well. |
 |
And thus we got And this did, in theory, make it easier for users to install various projects. |
 |
It also introduced a new type of built distribution, the "egg" distribution, because the existing ones weren't cutting it. There were other types of eggs too, but the built distribution type of egg is the important one. An egg was simply a zip file, with some metadata, could contain Python byte code as well. |
 |
The name "egg" comes from Python. Pythons lay eggs. |
 |
But |
 |
It was really good at installing. So easy! It couldn't uninstall... It couldn't tell you what you had installed...
And it mucked around with |
 |
So the solution was a new tool called
You might have never heard of Again, naming things is hard! |
 |
Thus We swapped redundancy for a recursive backronym.
So while |
 |
Because of all the problems with |
 |
At this point, people are starting to use Essentially, for an application there is no top-level package to install, so if we want a way to specify dependencies for an application, what do we do? |
 |
The solution is that |
 |
This gives us a familiar command, and allows for semi-reproducible environments. |
 |
So now everyone's happily Installing from PyPI is getting pretty slow. Remember, it's still just an index.
So when |
 |
Another problem this introduces is that as a package maintainer, my users have to trust 3rd party domains. What happens when I forget to re-register the domain my package is hosted on? An attacker can go and register it and put malicious code in place.
My users will have no idea. They are so used to |
 |
The solution to this is that PyPI needs to transition to literally hosting the distributions. |
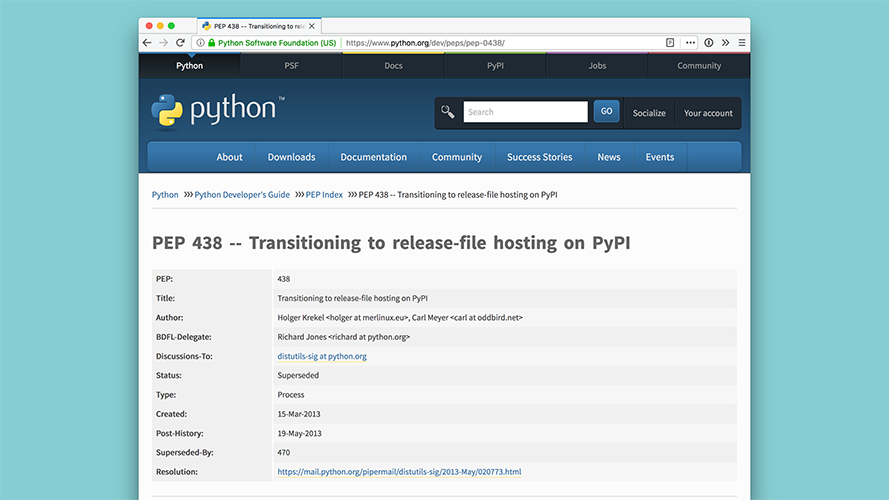 |
This is standardized in PEP 438, and PyPI becomes much faster. |
 |
Around this time we start to notice a new problem. As it turns out, all the problems we needed built distributions to solve are still problems! But we don't want eggs, eggs are bad. |
 |
The solution to this problem is the wheel distribution. This is another built distribution, and very similar to eggs, it's also just a zipfile.
This format has learned from the mistakes of |
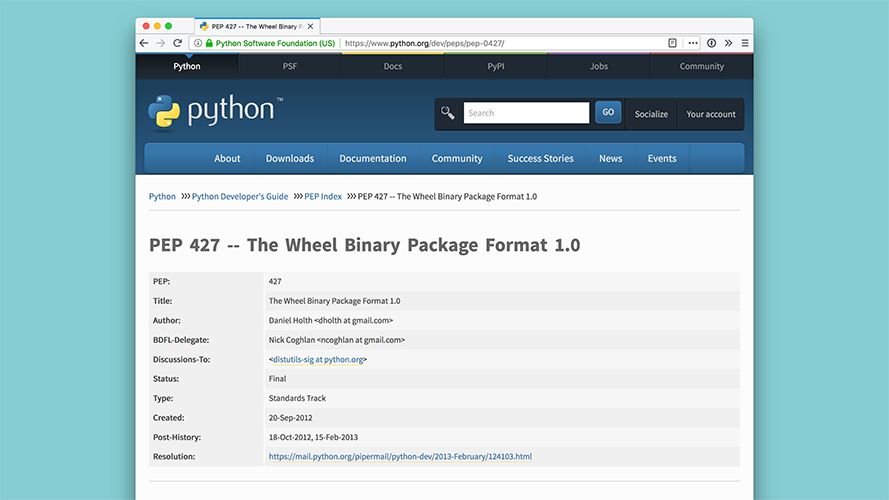 |
And, most importantly, it has a specification, PEP 427. There's also a convenient feature where you can look at a wheel file and tell what platform it's for just by the filename. |
 |
The name "wheel" came from a "wheel of cheese": you put wheels in a cheeseshop. I like to think the authors of the spec really got this name right, because in addition, nobody can say they're going to "reinvent the wheel". |
 |
At this point a lot of people are depending on PyPI, and we start to become a little more focused on making sure it's secure
And as it turns out, This means your PyPI credentials could be intercepted, or that you might not even be talking to PyPI at all. |
 |
The solution to this problem is |
 |
The name comes from tying up packages with twine before sending them.
This name doesn't really correlate well with what it does though. The
It just looks up some information about your package, and it knows how to send it, securely, to PyPI. It's more like a package carrier but... naming things is hard! |
 |
At this point we have a new problem: PyPI is starting to show it's age. |
 |
Here's PyPI in 2007, about four years old. |
 |
Here's PyPI in April of 2018, more than ten years later. |
 |
Here they are side by side. It's kind of like one of those "spot the difference" games. |
 |
It's not really fair to just visually compare PyPI in 2007 with PyPI in 2018. One big difference that might be hard to see is the number of packages went from less than 3K to more than 130K. In that time PyPI went from "a" place to get Python packages to "the" place to get Python packages. This growth included lots of issues with PyPI being down or having outages. And there were a lot of things that had to happen behind the scenes so that PyPI could continue to work. The other thing is that, by it's very nature, PyPI predates almost all of the packages that exist on it, including all of the web frameworks and testing frameworks you're familiar with. So it's fifteen years old, has pretty much no tests, doesn't use a modern web framework. To run it locally to do development, you actually have to go comment out large parts of it just to get it to run. What should we do? |
 |
Well, we could rewrite it all from scratch. Normally if you ask me if a full-stack rewrite, of a core piece of infrastructure, depended on by hundreds of thousands of users would ever succeed, I'd tell you no. |
 |
But it did. This is our new PyPI, and it's a complete rewrite. |
 |
It's also called Warehouse, as in a place to put packages (or cheese wheels). This is a project that started more or less in 2011, and had a number of goals, including HTTPS everywhere, using current best practices, a modern web framework, and tests! So many tests. |
 |
It officially became PyPI in in April of 2018. This was a tremendous undertaking which absolutely would not have been possible to have been completed in a reasonable amount of time without significant financial support from Mozilla. |
 |
So that's it, right? We've solved all the problems, we launched PyPI. Good job everyone! |
 |
No, we still have problems. But this is the nature of software! Once we build the new shiny thing, we start to realize what else it can do, or what the need actually is. |
 |
One problem is that packaging is still kinda hard, especially if you're new to it all. There are a lot of different tools and things you've never heard of until maybe today. |
 |
One solution to this problem is the Python Packaging Guide, at packaging.python.org. This is a really carefully crafted and well-maintained guide to Python packaging. |
 |
Another solution to this problem is the This represents the current best practices for creating a new Python package. |
 |
Another solution is just general care and maintenance. In general, I think these more modern projects are more well-specified, and easier to maintain. In addition, there is a serious focus on making these projects accessible to newcomers. |
 |
In fact, I would say that we have a new "problem" now. Python Packaging is perhaps a little too easy. |
 |
I could have called this talk "Python Packaging: So Easy a Spammer Could Do It". Having packaging be hard actually has some unintentional benefits. Namely, that folks that aren't truly invested in it can't figure out how to use it. Unfortunately this excludes a lot of people that don't have malicious intent, though. So while lowering that barrier is a priority, it does produce new problems like spam packages on PyPI. |
 |
There's another problem that's common these days: Maybe you need more than Python and Python libraries. Maybe you need R, LLVM, HDF5, MKL... maybe, you don't even have Python on your system yet. These problems are kind of outside the scope of the "Python Packaging", which assume that a) you have Python b) you really just want to do Python (and of course, sometimes some C). |
 |
But this is definitely within the scope of |
 |
Another problem we currently have is having an ergonomic way to specify reproducible environments.
The However, creating and maintaining this file can be challenging, and often we have multiple requirements files, for deployment, for development, for testing, for linting, etc. |
 |
The solution is the Pipfile specification. It's a single human-editable
file (
This file can be shared across multiple dependency-installing tools. If
you come from another ecosystem, this might feel familiar to
|
 |
Another problem is the ability to put arbitrary code in
However, it has problems as well. There's no way to truly predict what
dependencies a package will have without executing the
|
 |
The other problem I'll call the
" So while there do exist various solutions to the above problems, they're hard to implement and even harder to maintain. Also, it's very difficult to use anything else, as these are essentially the de-facto standard interface. Changing them becomes a bit of a chicken and egg problem. |
 |
The solution to this problem is PEP 517 and PEP 518. |
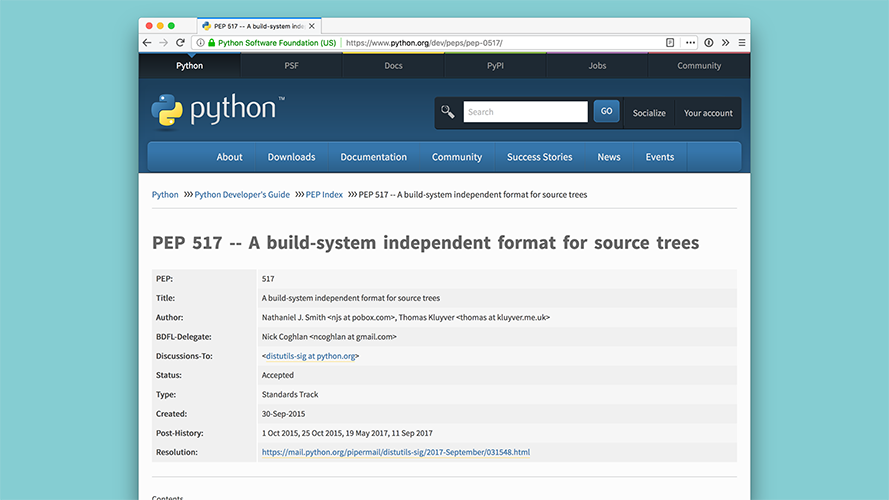 |
PEP 517 provides a minimal interface for installers like |
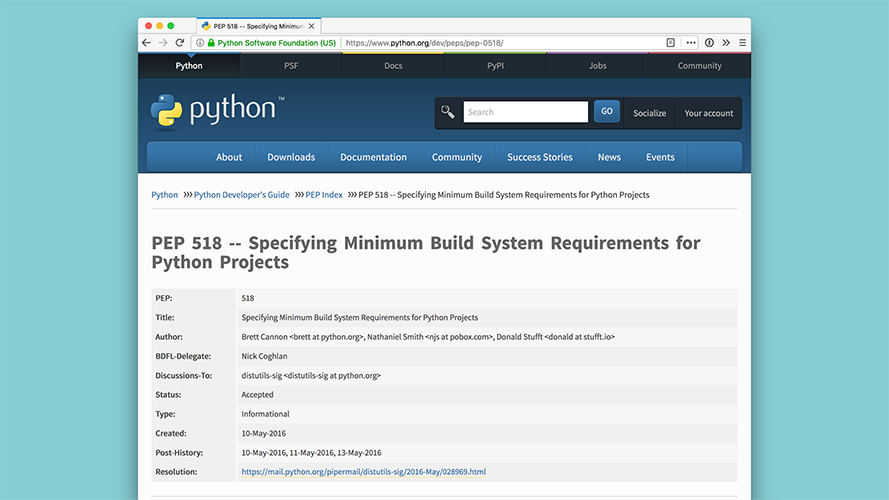 |
PEP 518 provides a way to specify the build system requirements for Python projects. These are dependencies you'd need to install a given package, not to run it. |
 |
Both these specifications use a new file, |
 |
That sounds like a lot of problems, you might say. Also consider that unlike Anaconda, unlike NPM, and with only a few small exceptions, Python Packaging is entirely volunteer-driven. So maybe you'd like to help. |
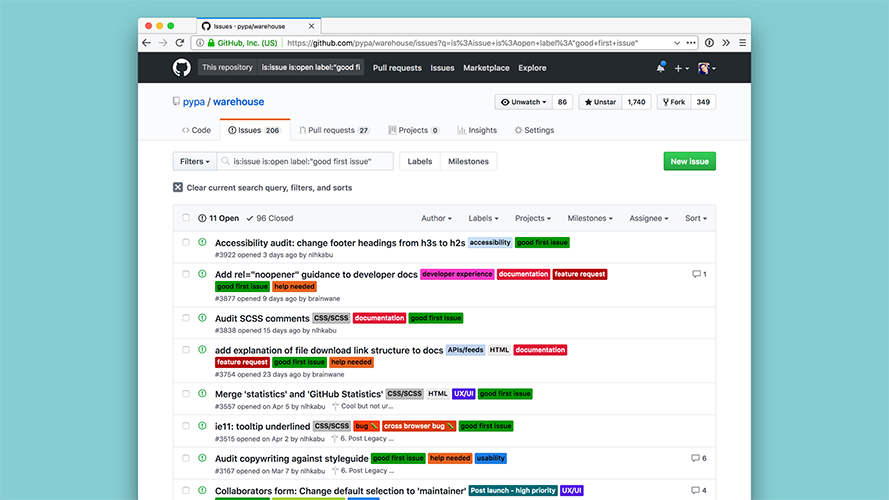 |
Most of the PyPA projects like PyPI and |
 |
We also do development sprints at various Python conferences and other events. If you're a contributor, come find me at one of these, and I'll be happy to give you one of these contributor stickers. |
 |
I've told you how to help us, here's how we can help you. |
 |
If you're having problems, you can do the following, in order of how quickly you need your problem solved, from "very quick" to "might take a while":
|
 |
To summarize: packaging isn't bad! But there are always going to be problems to be solved. We've made gradual changes over a long period of time, and each change is a response to an evolving need. Comparatively, it used to be really bad, and we might have for forgotten, or just never known, how hard it used to be.
So the next time you are frustrated with Python Packaging, imagine a world
with no And consider making a pull request. |
 |
Thanks! |